
The Intelligence Consolidation
Scaling laws reward consolidation, but investors are diversifying anyways


Over the past three years, we have seen the rise and fall of dozens of frontier AI labs.
In many cases, these labs have had shared investors: Sequoia Capital has invested in OpenAI, xAI, SSI, Reflection AI, Magic, Keen Technologies and Harmonic, while Andreessen Horowitz has invested in OpenAI, xAI, SSI, Character AI, Mistral AI, and Anysphere.
If you are investing in five or more AI labs, is that because you expect there to be an oligopoly where each oligopolist is a good investment, or do you simply lack conviction on who will win?
The former is a popular story, with a leaked 2023 Mistral memo claiming that “an oligopoly is shaping up”. At first glance, this tracks with API usage on OpenRouter:

One oligopoly story could be that different frontier AI labs are making different technical trade-offs, resulting in their own niche and specialties, and many of their fundraising announcements echo this sentiment:
Magic’s 2024 fundraise focused on their 100m token context window
Cohere’s Series C focused on enterprise use cases, like RAG and embeddings
Mistral’s initial memo focused on privacy and domain-specific finetuning
Adept’s launch focused on tool- and computer-use models
The proprietary trading industry
An industry that parallels this “many roads to Rome” quality is proprietary trading. Not only does it draw from a very similar talent pool as frontier AI labs, but it also sees strong differentiation between the few oligopolist players, due to the variety of asset classes and time horizons.
Secrets are all you need
Underpinning this differentiation is the incredible emphasis on secrecy. Beyond the “loose lips sink ships” culture that pervades the industry, all of these firms use non-competes that can be easily 3 years long. Even after you sit out this garden leave, you’ll still be bound by stringent confidentiality agreements.
These agreements are enforced litigiously. Perhaps the most famous and recent example is Jane Street suing Millennium, but this is not an isolated incident. Back in 2003, Millennium faced a similar lawsuit from Renaissance Technologies, and in 2014, G-Research used private prosecution to put one of their former researchers in prison for stealing their trading secrets.
This means these differentiated edges persist, helping firms preserve their market share in that asset class, even if they might otherwise struggle.
Flash boys: not so fast
One example of edge with this “secrets”-esque property of being difficult to replicate is the use of microwave tower networks to minimize trading latency.
Although its usage is well-known, optimal tower locations are severely limited, and there is only a limited amount of money to be made from being the fastest. Due to this steeply diminishing return, if you are a firm that has already invested heavily in this infrastructure, it might not be worth it for everyone else to engage in a red queen race to be faster than you.
Unsurprisingly, the industry has consolidated its investments. The microwave network in the Chicago-New Jersey corridor that connects America’s biggest exchanges boils down to three main groups:
McKay Brothers, which is used by IMC, Tower Research, Citadel Securities, SIG, Jane Street etc.
New Line Networks, which is run by Jump Trading and Virtu Financial
Vigilant Global, which is run by DRW
Thus, firms with access to this infrastructure can keep the market share available just by being fastest, since it is not worthwhile for new entrants to go after that edge.
Meanwhile, new players can go after new edges. For example, XTX Research, which famously is opposed to the low latency game, managed to break out and become the largest marketmaker in European cash equities in the span of a few years, thanks to their superior pricing and investment into AI data centers.

The combination of these two effects – the defensibility of secrets and diminishing returns to exploiting secrets – means proprietary trading has tended to be oligopolistic, with a few firms dominating each asset class where they have some persisting comparative advantage.
The bitter lesson strikes again
On the surface, it may seem like the different API use cases in AI map on to the different asset classes in proprietary trading, and each AI lab could focus on getting really good at one of them. For example, the top models on OpenRouter vary a lot by use case. In the recent weeks, these have been:
Gemini Flash 2.0: Roleplay, marketing, translation, legal, trivia, academia
Claude 3.7 Sonnet: Programming, SEO
GPT-4o-mini: Technology, science
DeepSeek V3: Finance
Gemma 3 4B: Health
However, the broader trend of overall usage makes this far less compelling, and suggests models have very limited sticking power. On average, a model only stays in the top 5 most used models for just over 6 weeks. This is drawn up by a few really long-lasting models, with the median landing at a mere 3 weeks. This is because API users tend to be very sensitive to performance.

So far, performance in AI has been defined by the Bitter Lesson: that “leveraging of computation” is more effective than leveraging “human knowledge of the domain”. Thus, performance improvements have not been isolated to specific niches, and instead depend on how much money is deployed on compute.
This means that secrets are much less important, and even if they were, the regulatory prohibition on non-competes in California, coupled with its open tech culture, means secrets do not stay secret for very long.
Scaling up to 2028
To put a number on compute, the jump between GPT-4 and GPT-4.5 over the past 2 years has involved increasing effective compute by two orders of magnitude, of which half came from algorithmic progress and half came from more physical compute. If we assume that algorithmic progress continues at its current rate and want to maintain the same overall rate of scaling, we’d need to increase physical compute by another 1.5 orders of magnitude from today to 20281.
Since GPT-4 took around $63M to train, the model in 2028 should take 300 times that, which is around $19B. A naive estimate for converting the training run costs into the capex spending required for the datacenter is to assume that the cost of the datacenter gets paid back by the total value of training runs you can do across its operational lifetime. Assuming a 4 year depreciation schedule, the GPT-4 training run which took 3 months (and 25000 A100s) implies a 16x multiple, giving a total cost of $1B.
With A100s going for $10k a pop, this gives a 4x multiple between the cost of the raw GPUs and the cost of the datacenter. As a sense-check, xAI's $700M Atlanta datacenter had around 12000 H100s and 370 A100s. H100s are around triple the price of A100s, leaving a GPU cost of $364M and a 2x multiple.
These bounds imply that a 2028 training run would require an upfront datacenter capex of anywhere between $152B and $304B. What are the market dynamics which this implies?
Incumbency in a capital intensive market
One analogy which has this similarly ramping capital intensity, and happens to be AI’s most critical upstream dependency, is chipmaking.
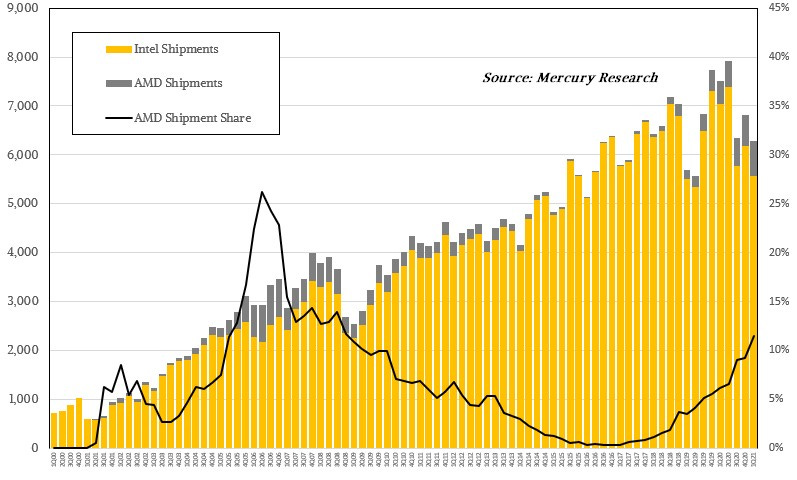
If we take a look at the CPU market, Intel became the dominant market player after IBM selected its x86 CPUs for the original IBM PC. Within 10 years, it had reached 80-90% market share. AMD would claw its way to 25% market share in the mid 2000s, drop back into irrelevance by 2015 and start gaining market share again in the late 2010s.
What this shows is that while a single generation of technical edge can help you grab market share, the economies of scale needed to amortize good research still gives the incumbent a lot of momentum. Thus the brief period of weakness in the mid 2000s was not enough, and it took a decade of Intel stagnation to truly break its monopoly.
High capex drives consolidation
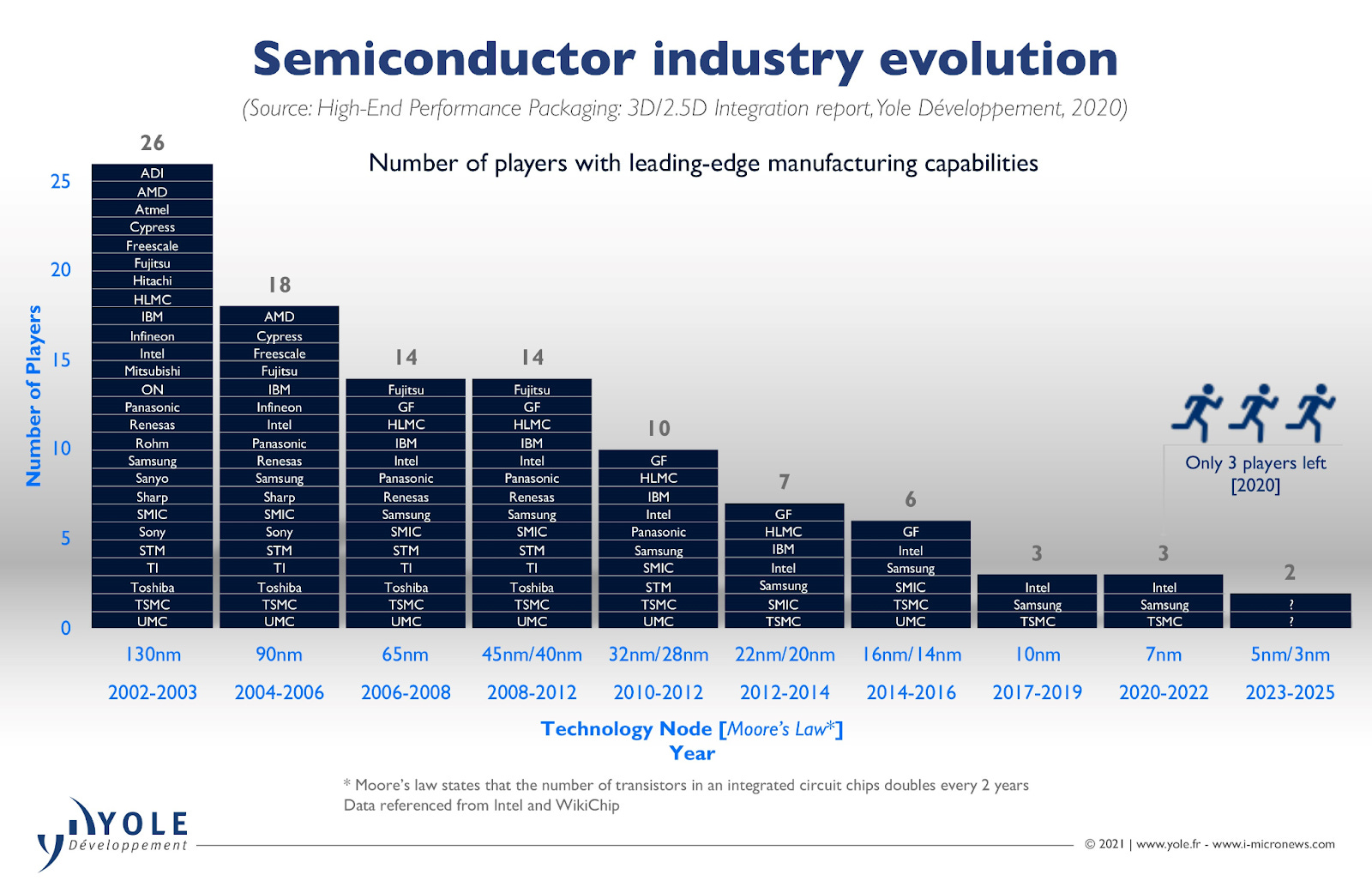
By default, this means that you should expect consolidation in these high capital intensity industries. This is exactly what you see in the foundry market too.
Moore’s second law states: the cost of a semiconductor chip fabrication plant doubles every four years. Although this law started to weaken in the 1990s, the cost of building a single advanced fab today is still 1,000x higher than in the early 1970s2.
As the cost of staying at the frontier rises, fewer firms can afford to compete. In the early 2000s, 26 foundries produced 130 nm nodes, but in 2020, only 3 foundries produced 7 nm nodes. Now only TSMC is at the frontier and accounts for around 67% of global market share.
Consolidation if scaling laws hold
If we look at the main funders of frontier AI labs, they're overwhelmingly big tech companies. Their capacity to finance these efforts can be roughly estimated from free cash flow and debt capacity (assuming a debt-to-EBITDA of 3):

The projected 2028 capex estimate of $152B to $304B presents significant financial challenges, even for big tech companies.
Consider Microsoft: the lower estimate of $152B would consume their entire cash reserves plus a full year's free cash flow (FCF). The upper estimate of $304B would require either all cash on hand plus four years of accumulated FCF, or alternatively, using up all their debt capacity.
Continuing the patronage for AI labs is becoming increasingly costly. If you believe that a handful of frontier labs will make it and don’t believe the oligopoly story, you are implying that all big tech companies will leverage their entire business just to sustain a handful of frontier AI labs. That’s not a straightforward bet to make.
Consumer
So far we’ve focused on the API market. The other half of frontier AI usage, and indeed the breakout product of ChatGPT, has been in consumer chatbots. This sub-industry looks even worse for oligopolies, since there is even less differentiation between the chatbots of labs.
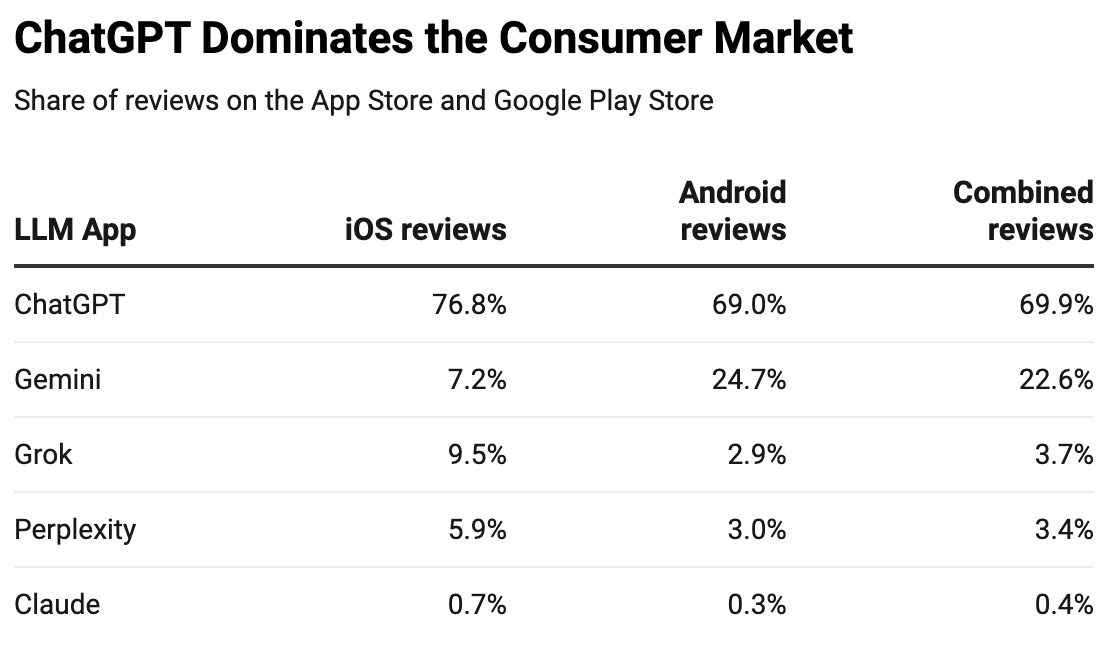
Instead, consumers tend to stay with the company they know best. Right now, that’s OpenAI, and that’s what we see when we take the number of reviews in the app stores as a proxy for market share.
Search is a consumer monopoly
This is not surprising. ChatGPT shares many characteristics with one of the clearest consumer monopolies today: web search.
User behaviour is sticky and habitual. Importantly, consumers don’t query the same thing across five search engines, but pick a search engine and stay for the long run. They do not have multi-vendor preferences.
It is then not surprising that there have only been two search monopolies thus far: Yahoo and Google. The Google monopoly formed because it was obvious to any consumer that Google was superior and they were already used to seeing Google results from the time where Yahoo used Google for search3.

For AI, that means that if a model company manages to build up a persistent lead that is so obvious to consumers on first try that you don’t need to rely on benchmarks, there is a chance of it taking the monopolist’s position.
The model is the market structure
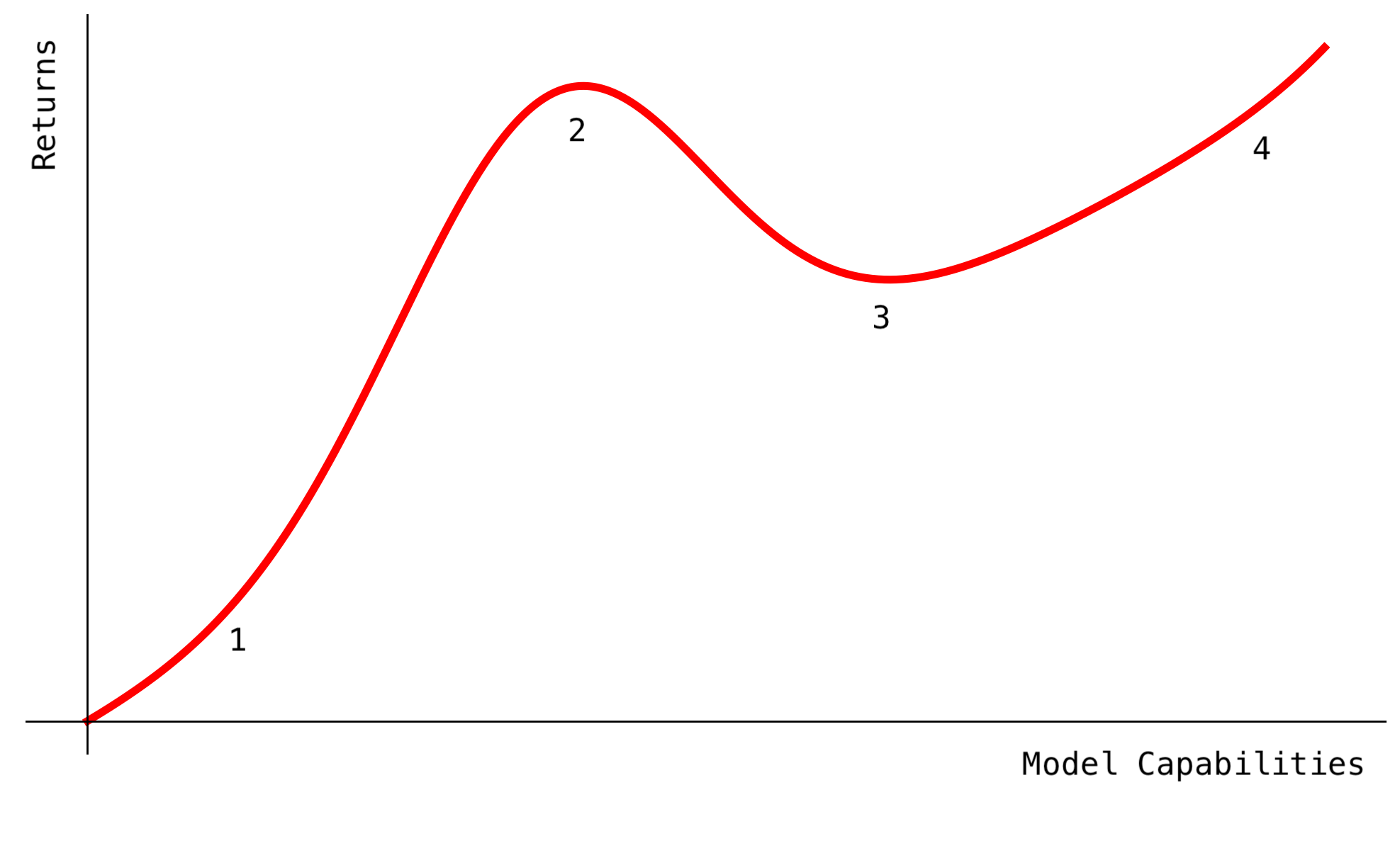
We can see that there are many different narratives for what happens to the market for frontier AI labs. These can be mapped onto different expectations about model capabilities.
If model capabilities stagnate at their current level, mostly products will be the ones which capture value, since open source models will commoditize the AI labs. This means that the value goes to the product and distribution, with the most value captured by a consumer monopoly.
If the scaling laws bend e.g. RL doesn’t generalize, model capabilities may continue to grow, but slower and only as basic research bets pay off. This means that each lab may end up finding their own niche for the type of research they are good at, and there will be an oligopoly of model providers who capture most of the value in each of their niches.
If the scaling laws hold until AGI, we can translate exponentially more compute into linear increases in intelligence and these linear increases into exponential or super-exponential economic returns. This creates strong incentives for more capex spend, and in turn, structural pressure to consolidate. Only a few of the labs will make it, with most bets on frontier AI labs being written to zero.
If we get beyond AGI to super-intelligence, then even research labs which are relatively commoditized will capture enormous value, owing to the size of the lightcone. However, it’s less clear if the current notions of property rights, value and returns are still as relevant.
At a portfolio level, the best case for the current spray-and-pray deployment of venture capital is case 2: indefinite optimism in some sort of AI progress, but without any clear conviction and with a long-term bet against scaling.
We would not bet against scaling! If you take scaling seriously, you end up in case 3: many of the enormous investments into frontier AI labs should be thought of as having the risk profile of early-stage investments but with the capital requirements of growth-stage investments. Diversifying on that basis isn’t prudent; it’s simply indecisive.
Thanks to Sam, Zeel, Atiyu, Arden and Mohit for reading drafts of this.
We expect there will be some technological improvements to reduce the cost of physical compute, but not enough to materially change the conclusions we draw here.
Today, a cutting-edge fab costs typically around $20 billion or more, and the TSMC fab in Arizona is projected to cost $65bn. In the late 1960s, a frontier fab cost around $4 million (~$31 million in 2025 dollars).
 | A guest post by
|
Love this!