


Pre-training isn't dead, it’s just resting
GPT-4.5, the value of RL, and the economics of frontier training


For two years after GPT-4, every model OpenAI released was smaller. On February 27, 2025, that finally changed. OpenAI launched GPT-4.5, calling it “the next step in scaling the unsupervised learning paradigm”. Here’s what people thought:




The launch video didn’t do the model any favours. Rather than focusing on GPT-4.5’s strengths, it highlighted how small the improvements were relative to GPT-4o and that it underperformed o3-mini, a 50x cheaper model.

Only a month and a half after the model’s release, they announced it was going to be deprecated.
Why did GPT‑4.5 disappoint?
When GPT-4 was released in 2023, it was seen as something fundamentally unprecedented. It blew past GPT-3.5 on the majority of benchmarks, and in some cases, saturated them entirely by reaching human-level performance.

GPT-4’s launch also came with a developer livestream full of feats that seemed unimaginable for GPT-3.5, such as converting a hand-drawn wireframe into a fully functioning website in a single request.
Where GPT-4 felt like a step change, GPT-4.5 felt like a letdown.
The biggest contributor to that was the many models released in between the two. Just from OpenAI, we saw updates to GPT-4, GPT-4 Turbo, the many iterations of GPT-4o, and the o-series of reasoning models. This made it hard to see the gains from purely increasing pre-training compute from GPT-4 to GPT-4.5 and begged the question: is pre-training a dead end?
Is Pre-Training A Dead End?
To answer this question, we need to know what happens when we only vary pre-training compute.
A natural experiment in scaling pre-training comes from Meta, who released 8 different text-only Llama 3 language models in 2024. The models range from 1B to 405B parameters, and since they came out over the course of only 8 months, we assume that there was relatively little compute efficiency improvement.
Based on these models, we can approximate a scaling relationship between the amount of pre-training compute and benchmark performance. This lets us extrapolate how GPT-4.5 should perform relative to GPT-4, since we know that it used 10x more pre-training compute than GPT-41.
What we find is that GPT-4.5 is on track with, if not beating, the pre-training trends2:



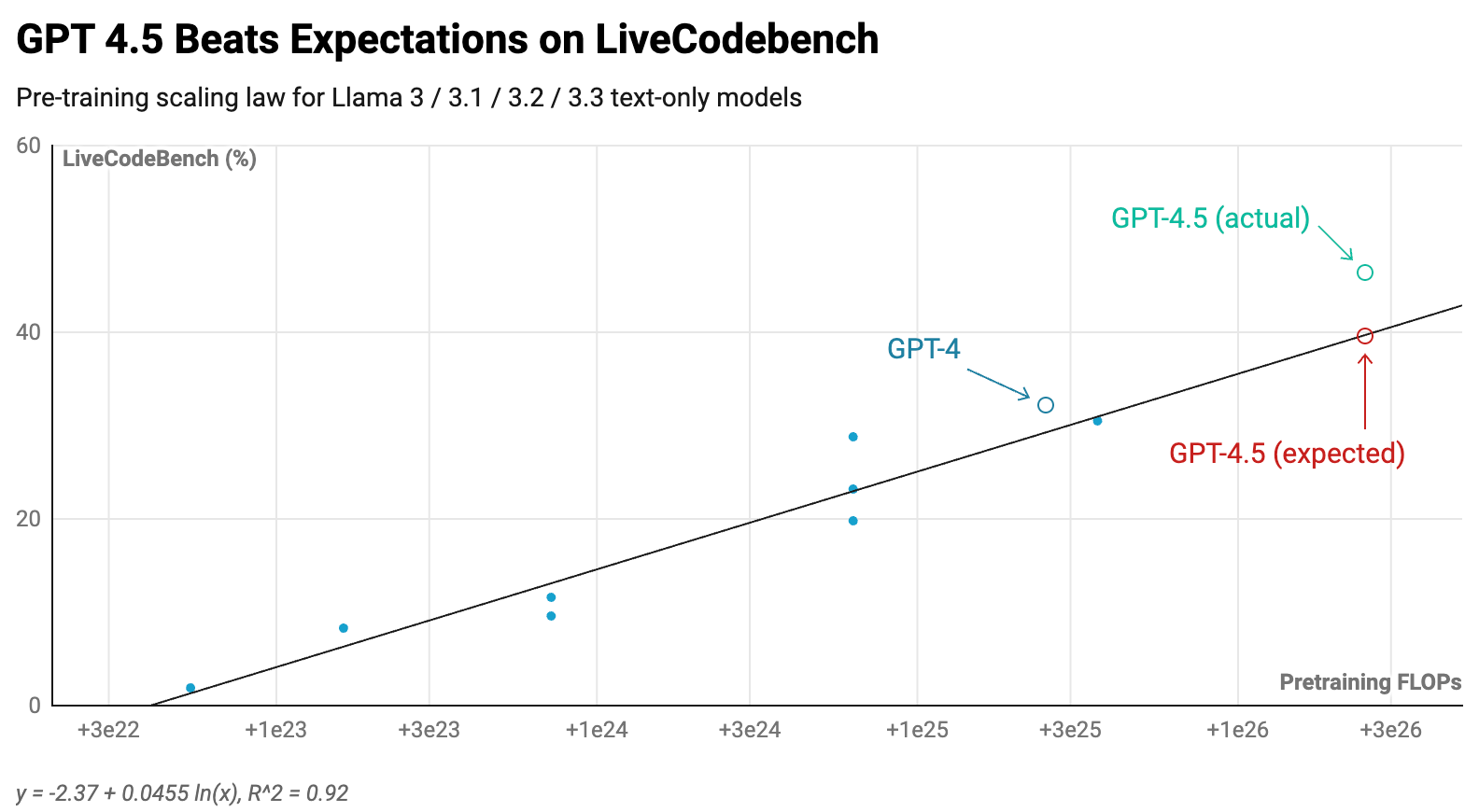
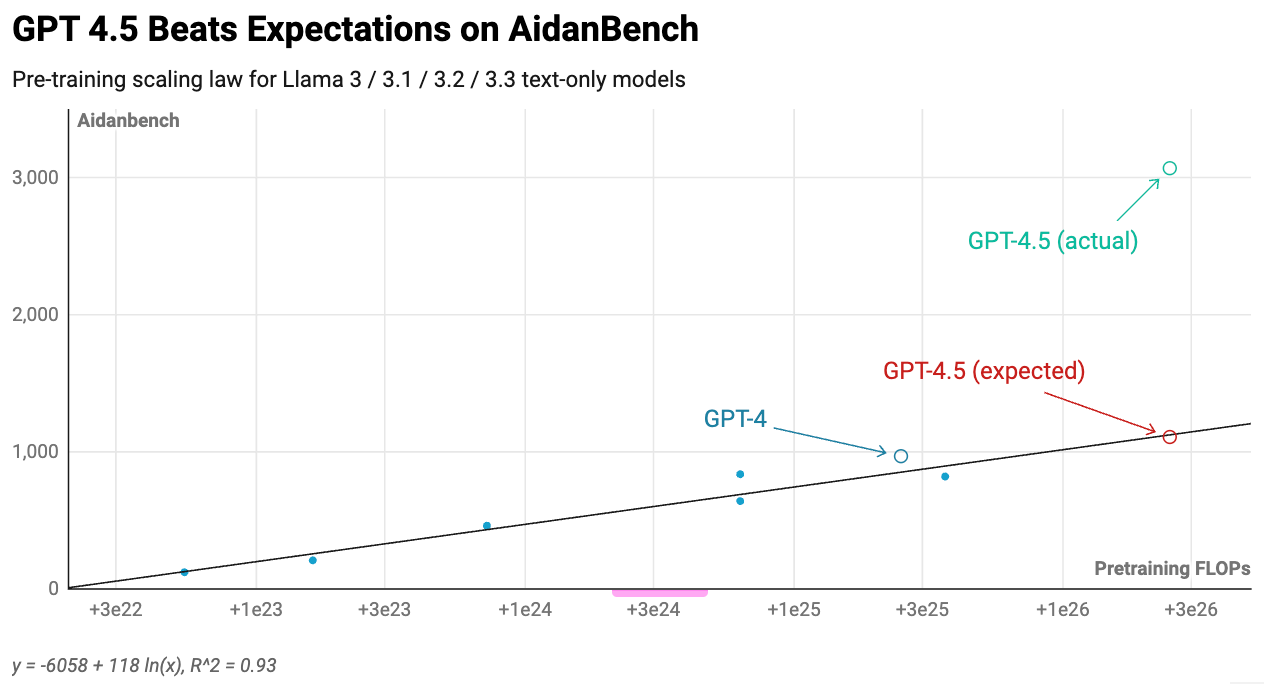


In other words, scaling still works. However, there’s a very good reason most frontier models have been smaller than GPT-43. It’s because researchers found ways to get better performance for far less money in other parts of the training stack.

Consider the models from the mid-2024 vintage, like GPT-4o and Claude Sonnet 3.6. They were 4 to 8 times smaller while still having comparable or better performance. This was driven by a range of techniques in mid-training and post-training:
Annealing on higher quality, distributionally different or longer context data
Instruction-tuning on synthetic data
Preference-tuning on human and AI feedback e.g. reinforcement learning from human feedback (RLHF)
Meanwhile, the late 2024 / early 2025 vintage, like o1 and o3, showed staggering results by doing reinforcement learning (RL) on chains of thought (CoT).
The Future of Model Training
Scaling RL and CoT is a very effective strategy for getting improvements at specific domains. That’s why the trend in the immediate future will be continuing in that direction. However, there will come a point when the industry’s focus will return to pre-training.
This is because of the economic realities of serving models.
Firstly, if customers have a range of different use cases, it will require doing RL training on a very large set of domains. This is especially because RL in one area can degrade unrelated capabilities. Models that have been RLHF’ed for chat are worse at playing chess than peers which are closer to just pre-trained models, and anecdotally, Claude 3.7 Sonnet feels more reward-hacky than its less RL’ed predecessor. Doing lots of RL is expensive4.
Secondly, if customers are using many CoT tokens at inference, models will become very expensive to serve. It will eventually become cheaper to have a bigger and smarter model which requires fewer CoT tokens to get the answer5.


It would be far cheaper if there were a way to make the model both more intelligent across domains and also more intelligent in absolute terms, such that it requires fewer tokens to get to the same quality output at inference time. This is exactly what pre-training gets you6.
Thus, pre-training will eventually come back and the OOMs of compute will continue to grow. Pre-training isn’t dead, it’s just resting.

Thanks to Aidan, Sam and Sheryl for reading drafts of this.
We estimate GPT-4’s pre-training compute to be 2.5e25. This is based on a few approaches. Firstly, there are reports that it had 280 billion active parameters and was trained on 13 trillion tokens, giving an estimate of 6 x 2.8E+11 x 1.3E+13 = 2E+25 FLOPs. Secondly, there are reports that it was trained on 25000 A100s for 3 months at 33% efficiency. Each A100 can do 312 TeraFLOPs per second, giving an estimate of 25000 x 90 x 24 x 60 x 60 x 3.12E+14 x 0.33 = 2E+25 FLOPs. Thirdly, the largest GPT-3 model took 3e23 FLOPs to pre-train and there is a 100x compute increase between GPT-n and GPT-n+1.
We estimate what GPT-4.5’s performance should be by plugging its pre-training compute into the estimated relationship directly. An alternative method is to take the difference in pre-training compute between GPT-4 and GPT-4.5 and use the estimated relationship to get the increase in performance expected from GPT-4.5 relative to GPT-4. Given the former came out two years later, this calculation should consider “effective compute” i.e. physical compute x compute efficiency. If we assume that we get 4x compute efficiency gains per year, this yields very similar results to our first method.
Epoch AI uses the inference cost of a model and tokens per second it is served at to approximate its size, giving an estimate for GPT-4o and Sonnet. We extend this to o1 and o3 using tokens per second data from Artificial Analysis.
For example, Anthropic CEO Dario Amodei has said that “the whole reason for scaling these models up was that the models weren’t smart enough to do RLHF on top of”. We also have evidence from open-source efforts that RL works much better on models with more pre-training compute.
 | A guest post by
|
This is a nice collection of plots. What is tough when comparing models across generations (i.e. gpt 3.5 to 4 to 4.5) is that post-training has gotten more effective and also potentially more focused on the evals of interest. It's very hard to know without access to the underlying base models.
Also, CoT isn't the only way for inference time compute. I bet most inference time compute has improvements that start as linear. Likely CoT too. Then, others like lightly parallel search will also stack on top of it.
Pretraining, and scaling all the paradigms at once, is just waiting on cluster buildouts. Still, more progress in post-training right now because iteration is easier.
this was well done—4.5 is criminally underrated