

Some people think of it purely in terms of intelligence. Today, the models are smashing academic olympiads left and right, as well as completing longer tasks up to 10 hours at a time. To them, it might feel like we’re pretty close to AGI.
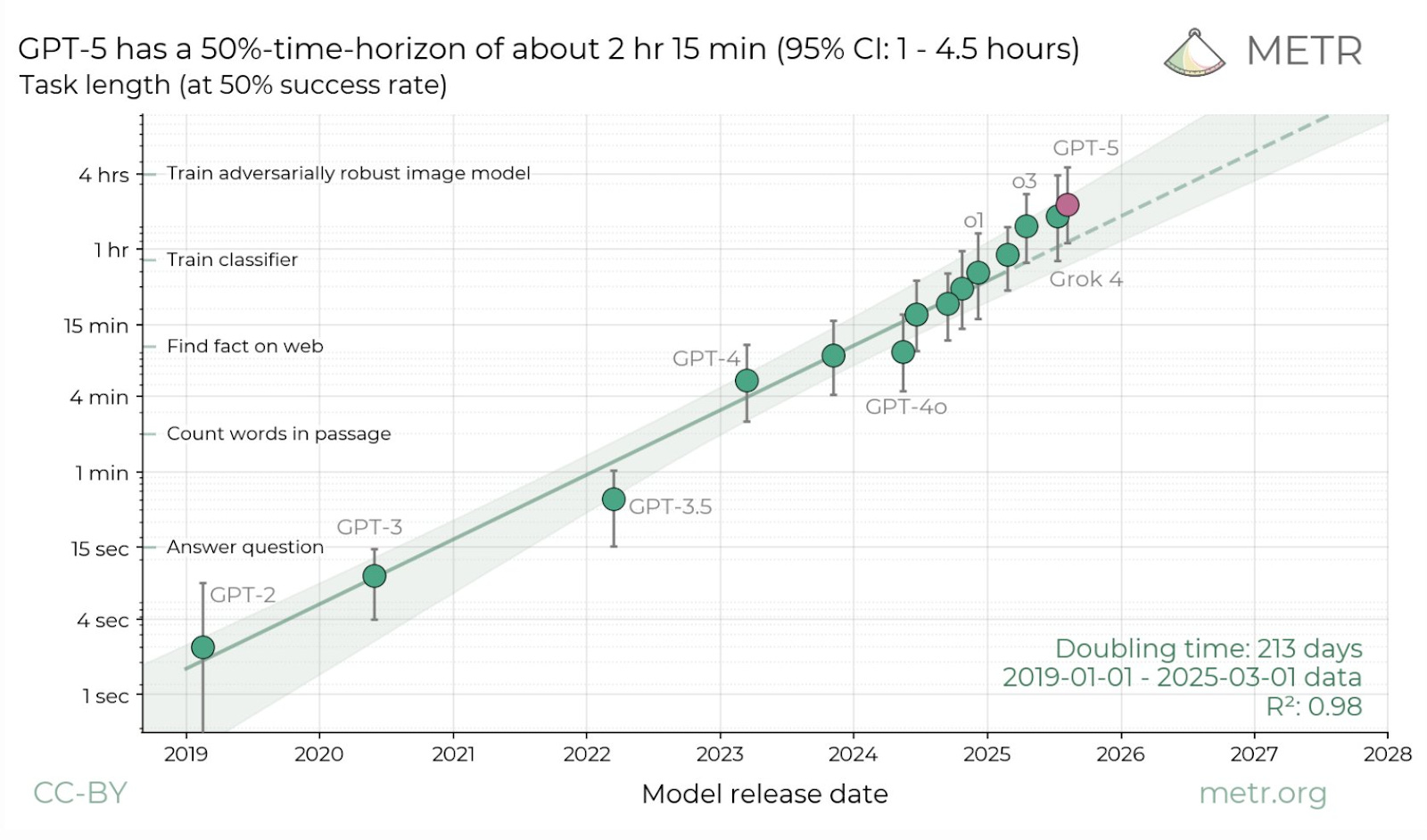
I went into university expecting to do an economics PhD, and switched to working on ML research due to some optimistic extrapolations of the GPT-3 paper, so my view of AGI is driven by its potential to be economically transformative.
From this perspective, the diffusion and impact of AI across the broad economy remains limited: you can see the AI age everywhere except in the productivity statistics.
Is there a capability overhang?
One explanation for this divergence is that products haven’t caught up to model intelligence. While there are valuable products which are yet to be created by scaffolding current models, this need for scaffolding reflects a deeper issue: people buy products for usefulness, not intelligence.
Usefulness requires agency, reliability, low cost and latency, alignment with user intent, integration with business processes, and much more. Along all of these dimensions, the models are simply not capable enough right now.
One direction which people have been betting on is using RL to bake these traits into the model, making it less reliant on scaffolding. RL seems to be very sample-efficient at getting domain-specific improvements, and certainly more cost-effective than pre-training.
Yet the majority of RL progress has been limited to a few domains like software engineering and competitive mathematics. Can we actually use it to accomplish economically valuable labour?
How do you apply RL to a real task?
The best way to understand this is to actually go after a real in-the-wild task, so I picked the problem of giving inline completions for financial data as you are typing.
This maps onto a decent chunk of work in finance, which is retrieving information when writing a memo or creating a deck. It is also an unsolved problem: there is no good inline autocomplete for writing, and certainly not one which retrieves financial data accurately. Large models are far too slow and expensive, while on-edge models struggle to chain tool calls, figure out when data is needed, and avoid making up numbers altogether.
To simulate this task, I populated a database full of 10-K and 10-Q data, synthetically generating many prompt-completion pairs using this data, as well as some prompts which did not require any completion.

Then I built an environment where a model would be given a prompt, as well as the ability to use a “search” tool to find the right information from the database and use a “return_answer” tool to either return the datapoint or an empty string for the no-completion cases. The answer would be judged on whether it was accurate compared to the ground truth pairs I had synthetically generated.
For evaluation, I held out some companies, time periods, metrics, and prompts, and as a baseline, I evaluated GPT-4.1, which achieved 80% accuracy with a p95 latency of 3.3 seconds. By contrast, Qwen 2.5 3B Instruct, which can be run locally on a laptop, achieved only 43% accuracy with a p95 latency of 2.6 seconds.
I then RL fine-tuned the Qwen model for a few hours on a single A100, and it went up to an accuracy rate of 93% while dropping its p95 latency to 1.1 seconds. In other words, it transformed the model into a genuinely useful product with frontier level performance at 3x the speed.
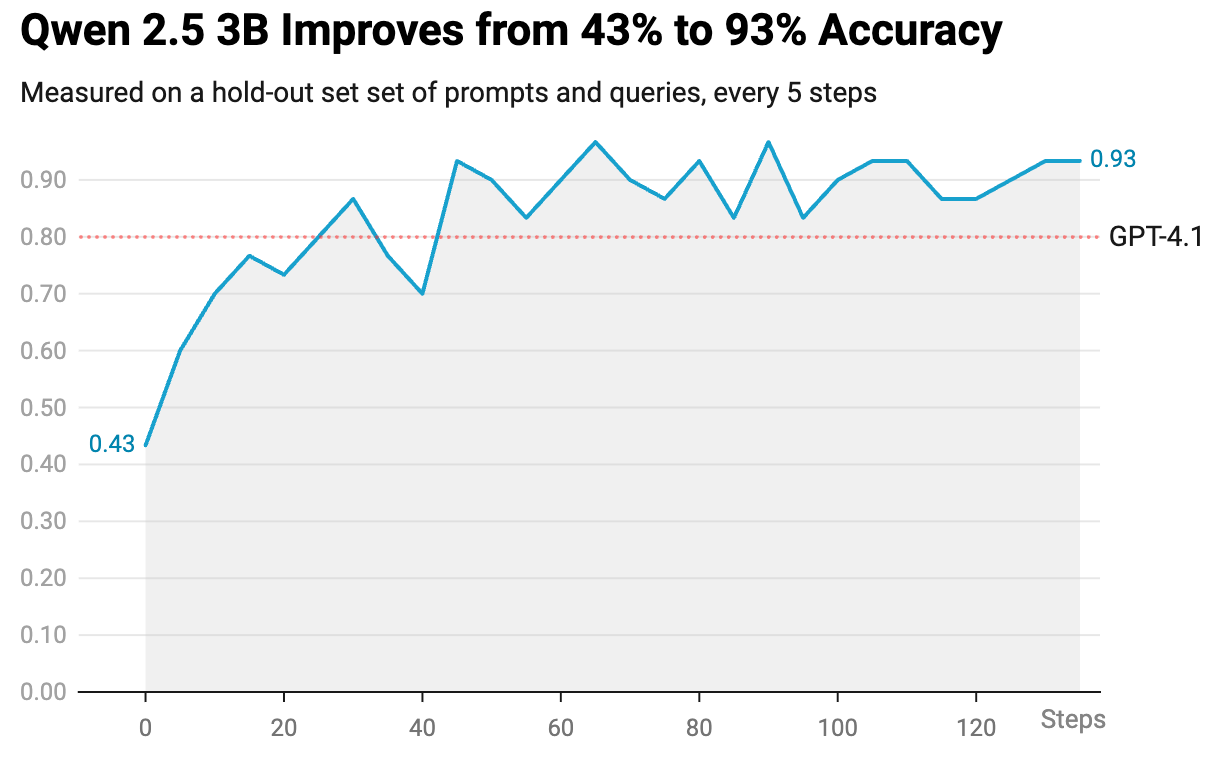
It seems like RL gives us a clear line-of-sight towards model improvements. If it’s such a free lunch, why isn’t everyone doing RL?
What are the footguns in applied RL?
Let me describe 4 lessons from doing this experiment, which make this less straightforward.
The first is the importance of obsessing over data quality: the “it” in the AI models is the dataset. For example, some of the financial metrics were getting saved with the wrong units, such that $9 billion was getting shown to the model as $9 billion billion. This is the kind of thing that can confuse a model, but is hard to notice without manually looking through lots and lots of rollout trajectories.
The second is that “model empathy” matters. Try and simulate what you would do if you had only the information it was given, and no additional context. This requires talking with the model a bunch, to calibrate on what the model knows.
For example, looking at the logs made me realise that the model was getting told that its tool calls were invalid, because it had used “selling, general & administrative” and “sg&a”, instead of “selling, general and administrative”. It’s just not very reasonable to expect a model to iterate through all the different ways of typing about a particular metric in order to figure out which is acceptable, so I made the environment more tolerant of different names for the same thing.
The third is that reward shaping is hard, reward hacking is always looming, and every step forward can feel like a step back.
Here’s an illustration:
You start by giving the model only a reward signal depending on correctness.
This is very sparse, so the model struggles to learn to reason about tool use.
You add a reward signal on the intermediate steps e.g. rewards for using the “search” tool correctly, penalties for using “search” in a no-completion case or too many times.
The model only returns “no completion needed”.
You do some back-of-the-envelope-calculations and realise that with the relative weights of the rewards and penalties, the likelihood of it getting at least one wrong tool call, and the fraction of the dataset which is no-completion, the expected value of trying to answer is less than simply giving “no completion needed” every time.
You re-adjust the weights, but notice that the model now brute forces by using many turns to try many different tool calls, so you impose a maximum number of turns.
The model suddenly seems to be performing well, but the number of turns has gone up.
You take a look and realise that the model is spamming non-ASCII characters in each turn and hitting the maximum turn limit. This leads the environment to return “No response” to the judge, which takes that to be correct in the no-completion cases.
In other words, you need to be paranoid every step of the way.
The fourth is a corollary of the three above, which is that tooling matters. One part of this is observability e.g. inspecting the data, seeing what the model is seeing, and tracking what is happening in the rollouts. A lot of the time spent babysitting a training run is spent on looking through metrics on wandb, and using them to diagnose if issues are arising e.g. right as the model went into the weird bit of the policy which involved spamming non-ASCII characters, both the KL divergence and the gradient norm spiked.
The other part of tooling is the infrastructure to make iterations faster. This can help with the more usual ML science e.g. sweeping hyperparameters, but it is especially useful for RL, since the speed of your rollouts can make a big difference to wall clock time due to a larger fraction of training being spent on inference.
What determines the right to win?
None of these pitfalls are individually intractable, but the reason they nonetheless deter many folks from applying RL is because they require the co-design of product and research.
Unlike pre-training, you aren’t trying to just improve capabilities broadly, but instead you are after a specific goal in RL. This means you need to know how the model fits into the end product, so that you can decide on what the right data and environment is, as well as what to optimise for and how to craft the right rubric.
Figuring this out looks a lot like what I spent time doing as a founder i.e. talking with customers, dealing with the enterprise sales cycle, and finding an internal champion at the company. In many cases, what is most helpful to getting a customer to conviction is being able to give them a working demo very quickly, which they can play with and use to advocate internally.
At the same time, your ability to ship quickly is so dependent on the research tooling. This project took me a bit over a week, but much of that was spent debugging infrastructure issues. Now that I have done it once, I can recycle it for the next project, and the one after that,
Very few teams are set up to ship at startup speed while also building a reusable research platform. One view from the full-stack AI startups and the private equity rollups is to run a “services-to-product” playbook that starts with owning a vertical and gradually building the tooling around it.
However, I’m actually more excited for a different approach, one where the frontier AI labs and RL-as-a-service companies leverage the infrastructure they have to rapidly deploy across domains. Unlike incumbents at many other points in history, these companies are still incredibly young.
They also have an advantage in cost structure, since they can amortise fixed research costs and bring down the average cost of each deployment. Their ownership of the research means they can integrate traits they care about into the training pipeline e.g. baking in certain general capabilities into pre-training to make RL easier or distilling smaller models to make inference cheaper.
If they can scale this co-design of product deployment with model research, we have a real shot at AGI, not just as a singular academic milestone, but as a diffuse economic achievement.